Workshop 6. Shell Scripts and Cluster Computing¶
Shell scripts¶
Shell scripts are files that contain commands that are understood by a shell
program (e.g. bash). All of the commands that can be run on a command line
may also be included in a shell script, but there are some features in shell
scripts that are not available on the command line.
Basic shell script¶
The most basic shell script is a file that has a single command in it.
Typically, shell script filenames end in .sh, to indicate they are shell
scripts. For example:
$ cat list_10_biggest_files.sh
du . | sort -nr | head
The shell script example above contains one command line command that prints to the screen the top ten largest files under the current directory. Shell scripts may contain as many valid command line commands as desired.
Shell scripts may be created using any regular text editor.
Running shell scripts¶
This shell script may be run in one of two ways:
$ bash list_10_biggest_files.sh # method 1
319268 .
221556 ./content
221552 ./content/workshops
217880 ./content/workshops/05_ngs_app_session_2
5356 ./.build
4384 ./.build/html
4344 ./.git
4180 ./.git/objects
2780 ./content/workshops/04_R
1436 ./.build/html/_downloads
$ . list_10_biggest_files.sh # method 2
319268 .
221556 ./content
221552 ./content/workshops
217880 ./content/workshops/05_ngs_app_session_2
5356 ./.build
4384 ./.build/html
4344 ./.git
4180 ./.git/objects
2780 ./content/workshops/04_R
1436 ./.build/html/_downloads
In the first method, the command bash invokes a new bash shell, executes the
commands in script inside the new shell, and exits. In the second method, the
commands in the script are executed as if they had been typed on the current
command line. This distinction may be important depending on what variables are
defined in the script (see Environment and user defined variables below).
Specifically, if a variable is defined in the current shell environment and
redefined in the script, the first method will preserve the local environment
variable, while the second does not:
$ cat my_script.sh
MYVAR=junk # (re)define the variable named MYVAR
$ MYVAR=stuff # define the variable MYVAR in the current environment
$ echo $MYVAR
stuff
$ bash my_script.sh
$ echo $MYVAR
stuff
$ . my_script.sh
$ echo $MYVAR
junk
The . method has overwritten the local variable MYVAR value, while the
bash method does not.
Making shell scripts executable¶
There is a third method for executing shell scripts that involves making the script executable.
Linux file permissions
Every file in a linux operating system has a mode that defines which
operations a given user has permission to perform on that file. There are
three types of modes: read, write, and execute. These mode types may be
assigned to a file for three different types of users: owner, group, and
others. Each file has an owner and a group associated with it, and the
mode of the file may be inspected using the ls -l command:
$ ls -l my_script.sh
-rw-r--r-- 1 ubuntu ubuntu 12 Oct 14 17:24 my_script.sh
Here, the output of ls -l is interpreted as follows:
permissions
-----------
owner last
| group modified
| | others group date
/ \/ \/ \ / \ / \
-rw-r--r-- 1 ubuntu ubuntu 12 Oct 14 17:24 my_script.sh
| \ / | \ /
| owner file filename
num size
hard
links
See this page for more information on linux file permissions.
By default, files created will have a mode such that the creator may read and write the file, and users in the file’s group and others may only read the file. To make a file executable, the execute mode on that file must be set appropriately:
$ ls -l my_script.sh
-rw-r--r-- 1 ubuntu ubuntu 12 Oct 14 17:24 my_script.sh
$ chmod a+x my_script.sh
$ ls -l my_script.sh
-rwxr-xr-x 1 ubuntu ubuntu 12 Oct 14 17:24 my_script.sh
Any user on the system now has access to execute this script.
In addition to setting the execute mode on the script, executable shell scripts
must also have a shebang line. The shebang line in a bash script looks like
#!/bin/bash. This must be the first line on the shell script, e.g.:
$ cat my_executable_script.sh
#!/bin/bash
MYVAR=junk
Note
The shebang line tells the shell which program should be used to run the
commands in the script. It always starts with #!, followed by a command
that can understand the contents of the script. For example, python scripts
may be made executable by setting the executable mode on the file as above
and adding #!/usr/bin/python at the top of the python script. Note the
program specified uses an absolute path, i.e. /usr/bin/python instead of
just python. It is good practice to specify the absolute path to the
desired program in the shebang line, which can be identified for a given
command on the path using the which command:
$ which python
/usr/bin/python
The # symbol is often called ‘hash’, and the ! symbol is often called
‘bang’ in linux parlance. Thus, shebang is the inexact contraction of ‘hash’
and ‘bang’.
Once the execute mode is set on the script and the appropriate shebang line has been specified, the script can be run as follows:
$ ./my_script.sh
Running scripts in this way is equivalent to the bash my_script.sh form.
Executable shell scripts may always be run by the other two methods mentioned in
Running shell scripts as well as with the ./ prefix.
bash scripts¶
Scripts that include commands from the bash language are called bash scripts. bash has many language features, but some are only conveniently implemented in scripts, while others are exclusively available in scripts. This section covers the key concepts of bash that are useful in writing scripts.
Environment and user defined variables¶
The bash program supports storing values into variables, similar to other languages. Variables in bash are typically named in all capital letters and underscores, but this is not required, e.g.:
$ MYVAR=stuff
$ nonstandard_but_valid_bash_variable_name=other stuff
The values stored in a variable are always stored as a string; there are no numeric types in bash.
Important
When defining a shell variable, there must be no spaces between the variable name and the equals sign. For example, the following definition throws an error:
$ MYVAR = stuff
bash: MYVAR: command not found
Note
There are many environment variables defined by bash by default. To see a
list of them, use the env command:
$ env | head
APACHE_PID_FILE=/home/ubuntu/lib/apache2/run/apache2.pid
MANPATH=/home/ubuntu/.nvm/versions/node/v4.6.1/share/man:/usr/local/rvm/rubies/ruby-2.3.0/share/man:/usr/local/man:/usr/local/share/man:/usr/share/man:/usr/local/rvm/man
rvm_bin_path=/usr/local/rvm/bin
C9_SHARED=/mnt/shared
C9_FULLNAME=Adam
GEM_HOME=/usr/local/rvm/gems/ruby-2.3.0
NVM_CD_FLAGS=
APACHE_RUN_USER=ubuntu
SHELL=/bin/bash
TERM=xterm-256color
Shell expansion¶
Certain expressions in bash result in shell expansion, where the expression is
literally substituted with another string before a command is executed. The
simplest shell expansion type is shell variable expansion, which is accomplished
by prepending a $ to the variable name, optionally surrounding the variable
name in curly braces:
$ MYVAR=stuff
$ echo $MYVAR
stuff
$ echo ${MYVAR} # equivalent to above
stuff
Above, the value of MYVAR is literally replaced in the echo command before
it is run. This type of shell expansion is useful for, e.g. storing a filename
prefix and used to create multiple derivative files, e.g.:
$ PREFIX=file_sizes_top
$ du . | sort -nr | head -n 10 > ${PREFIX}_10.txt
$ du . | sort -nr | head -n 100 > ${PREFIX}_100.txt
$ du . | sort -nr | head -n 1000 > ${PREFIX}_1000.txt
$ ls
file_sizes_top_10.txt file_sizes_top_100.txt file_sizes_top_1000.txt
You can use as many variable expansions in a command as desired. For example, we could perform the same operation above using a variable for the number of top largest files:
$ PREFIX=file_sizes_top
$ NUM=10
$ du . | sort -nr | head -n $NUM > ${PREFIX}_${NUM}.txt
$ NUM=100
$ du . | sort -nr | head -n $NUM > ${PREFIX}_${NUM}.txt
$ NUM=1000
$ du . | sort -nr | head -n $NUM > ${PREFIX}_${NUM}.txt
$ ls
file_sizes_top_10.txt file_sizes_top_100.txt file_sizes_top_1000.txt
Warning
bash does not require that a variable be defined to substitute it into a command. If a variable expansion is used on a variable that does not exist, the empty string will be substituted:
$ PREFIX=file_sizes_top
$ du . | sort -nr | head -n 10 > ${PERFIX}_10.txt # <- typo!
$ ls
_10.txt
These are some of the useful environment variables that are defined by default in bash:
$ echo $PWD # absolute path to present working directory
$ echo $PATH # the set of directories bash searches to find commands run
# on the command line
$ echo $RANDOM # returns a random number in the range 0 - 32767
$ echo $HOSTNAME # the host name of the computer you are currently working on
Command expansion¶
Similar to variable expansion, bash has two ways to take the output of one bash
command and substitute it into another. The syntax is either `<command>`
or $(<command>):
$ basename my_script.sh .sh # removes prefix path elements and .sh extension
my_script
$ BASENAME=$(basename my_script.sh .sh)
$ echo $BASENAME
my_script
$ BASENAME=`basename my_script.sh .sh` # equivalent to above
$ echo $BASENAME
my_script
This form of expansion can be useful for making bash scripts generic when passing in a file on the command line upon execution (see Command line arguments below).
Variable manipulation¶
Variables in bash have special syntax for manipulating the value of the strings contained within them. These manipulations include computing the length of a string, substituting a portion of the string with a regular expression, stripping off a particular pattern from the beginning or end of a string, etc. These are some of the more useful examples:
$ VAR=ABCABC123456.txt
$ echo ${#VAR} # length of VAR
16
$ echo ${VAR:3} # value of VAR starting at position 3 (0-based)
ABC123456.txt
$ echo ${VAR:3:5} # string of length 5 starting at position 3
ABC12
$ echo ${VAR%%.txt} # remove longest occurence of .txt from end of VAR
ABCABC123456
$ echo ${VAR/ABC/XYZ} # replace first occurence of ABC with XYZ
XYZABC123456.txt
$ echo ${VAR//ABC/XYZ} # replace all occurences of ABC with XYZ
XYZXYZ123456.txt
See the Manipulating Strings page of the bash language reference for more types of string manipulations.
Command line arguments¶
Bash scripts can access command line arguments passed to the script using special
variables $0, $1, $2, $3, etc. $0 expands to the name of the
executed command, which depends on how the script was executed:
$ ls -l my_script.sh
-rwxr-xr-x 1 ubuntu ubuntu 12 Oct 14 17:24 my_script.sh
$ cat my_script.sh
#!/bin/bash
echo $0
$ bash my_script.sh
my_script.sh
$ . my_script.sh
bash
$ ./my_script.sh
./my_script.sh
$1 expands to the first command line argument, $2 expands to the second,
and so on:
$ cat my_script.sh
#!/bin/bash
echo $0, $1, $2, $3
$ bash my_script.sh arg1
my_script.sh, arg1
$ . my_script.sh arg1
bash, arg1, ,
$ ./my_script.sh arg1
./my_script.sh, arg1, ,
$ ./my_script.sh arg1 arg2
./my_script.sh, arg1, arg2,
$ ./my_script.sh arg1 arg2 arg3
./my_script.sh, arg1, arg2, arg3
$ ./my_script.sh arg1 arg2 arg3 arg4
./my_script.sh, arg1, arg2, arg3
The positional variables behave just like any other bash variables in a script.
One additional variable that is sometimes useful is $#, which expands to
the number of command line arguments passed on the command line:
$ cat my_script.sh
#!/bin/bash
echo $#
$ ./my_script.sh
0
$ ./my_script.sh arg
1
$ ./my_script.sh arg arg
2
Another variable that is also useful is $@, which is a string of all the
command line arguments in one variable:
$ cat my_script.sh
#!/bin/bash
echo Arguments: $@
$ ./my_script.sh
Arguments:
$ ./my_script.sh arg1
Arguments: arg1
$ ./my_script.sh arg1 arg2 arg3
Arguments: arg1 arg2 arg3
Conditional statements¶
bash supports conditional statements and constructs. Below are several examples of how to write conditional expressions:
[ <operator> <value 2> ] # test on value 2
[ ! <operator> <value 2> ] # negated test on value 2
[ <value 1> <operator> <value 2> ] # comparative test of value 1 and 2
[ ! <value 1> <operator> <value 2> ] # negated test on value 1 and 2
In the above examples, the spaces are important; all terms, including the [
and ] must be separated by spaces.
Command exit status
Every command executed in a bash shell returns an integer called an exit status.
The exit status of a command indicates what happened during the execution of
the command. Typically, 0 means the program executed successfully and any
other number means there was a failure. The exit status of the last
executed program is automatically stored into the environment variable $?.
For example:
$ echo hello
hello
$ echo $? # exit status of previous echo command
0
$ cat nonexistent_file.txt
cat: nonexistent_file.txt: No such file or directory
$ echo $? # exit status of previous cat command
1
The exit status of 1 means the cat command failed. The exit status of each command can be used to implement conditional logic based on the success or failure of commands run in a script.
The conditional expressions above have no output but produce an exit status of 0 or 1 based on evaluation of the test:
$ [ "a" = "a" ] # test if "a" and "b" are lexicographically identical
$ echo $?
0
$ [ "a" = "b" ]
$ echo $?
1
$ [ -z "" ] # test if the value is empty
$ echo $?
0
Here are some of the common useful operators that can be used to construct conditional statements:
# all of these examples evaluate to 0 (true)
# for strings
"a" = "a" # test for lexicographical equality
"a" != "b" # test for lexicographical inequality
-z "" # test whether value has zero length
-n "a" # test whether value does not have zero length
# for integers
1 -eq 1 # test for integer (non-lexicographic) equality
1 -ne 2 # test for integer inequality
1 -gt 0 # integer greater than test
1 -ge 1 # integer greater than or equal to test
1 -lt 0 # integer less than test
1 -le 1 # integer less than or equal to test
# for files
-e hello_world.qsub # test if file or directory exists
! -e hello_world.qsub # test if file or directory does not exist
-f hello_world.qsub # test if the argument is a regular file
# (i.e. not a directory, pipe, link, etc)
-d dir/ #test if the argument is a directory
-s nonempty_file.txt # test if the file has non-zero contents
Conditional statements can be used in two ways. The first is as guards in
command line commands that use the logical operators && and ||:
$ cat nonexistent_file.txt
cat: nonexistent_file.txt: No such file or directory
$ [ -e nonexistent_file.txt ] && cat nonexistent_file.txt
$ # cat was not executed, because the initial test fails
The && operator is a logical AND operator for exit statuses. It can be used
in between two separate commands to short-circuit command execution. In the above
example, chaining the file existence test before the cat command prevents the
latter command from running and failing if the file does not exist. If the file
does exist, the file existence test passes and the cat command is executed as
expected. When chaining together commands in this way, a command will continue
executing subsequent commands as long as the current command evaluates to an
exit status of 0.
The || operator is a logical OR operator for exit statuses. It can be used to
construct more complicated conditional logic on a single line. For example:
$ ls new_file.txt existing_file.txt
ls: cannot access new_file.txt: No such file or directory
existing_file.txt
$ [ ! -e new_file.txt ] && touch new_file.txt || \
ls new_file.txt existing_file.txt
existing_file.txt new_file.txt
In the above example, the ls command runs regardless of whether new_file.txt
exists or not, because we create it only if it does not already exist.
bash also supports if statement syntax:
if [ ! -e new_file.txt ];
then
touch new_file.txt
else
# do nothing, else not necessary here,
# just including for illustration
fi
ls new_file.txt existing_file.txt
This example has the same effect as the previous inline example using && and
||. The if statement syntax can be specified on the command line as well
as in scripts, if desired:
$ if [ ! -e new_file.txt ]; then touch new_file.txt; fi
$ ls new_file.txt existing_file.txt
existing_file.txt new_file.txt
Conditional expressions can also be used with the while looping construct,
for example:
while [ ! -e server_is_up.txt ];
do
echo Checking if server is up...
curl www.my-server.com > /dev/null
if [ $? -eq 0 ];
then
touch server_is_up.txt
else
sleep 5 # curl exited with an error, wait five seconds
fi
done
This example uses the sentinal file pattern, where the file server_is_up.txt
is used to indicate the state of another process.
See the bash reference on tests for more complete description of conditional expressions and tests.
for loops¶
bash supports for loop constructs. The for loop is especially helpful
when a number of files or values must be iterated for each execution of the script.
For example, we could create a backup of every text file in the current directory:
#!/bin/bash
for fn in *.txt
do
cp $fn ${fn}_bak
done
The syntax of the for loop goes like:
for <iter varname> in <expression>
do
<commands>
done
Here, <iter varname> can be any valid bash variable name, and <expression>
can be any list of values or valid shell expansion. Note in the backup example
above the expression can be a glob. By default, the for loop iterates on each
space-delimited value in <expression>, for example:
# these loops all print out 1-4 on individual lines
# list of values
for i in 1 2 3 4
do
echo $i
done
# variable expansion
MYVAR="1 2 3 4"
for i in $MYVAR
do
echo $i
done
# command expansion
for i in $(seq 1 4)
do
echo $i
done
The command expression example can be very useful when running some number of trials of an analysis, for example:
NUM_TRIALS=10
for i in $(seq 1 $NUM_TRIALS)
do
# assume ./run_trial.sh exists and runs some randomized analysis
./run_trial.sh > trial_${i}.txt
done
It may also be useful to write a script that processes each argument on the
command line separately using $@:
$ cat my_script.sh
#!/bin/bash
for i in $@;
do
echo $i
done
$ ./my_script.sh
$ ./my_script.sh 1 2
1
2
$ ./my_script.sh 1 2 3 4
1
2
3
4
Cluster Computing¶
Cluster computing is a strategy to enable the efficient utilization of a large number of computers connected together in a shared setting. As computational needs have grown, dedicated computing facilities with hundreds or thousands of individual computers have been established to run larger and larger scale analyses. This development presents a new set of challenges to system administrators and end users in how to manage and use these large numbers of connected computers.
Cluster concepts¶
Clusters are typically organized similarly to the following illustration.
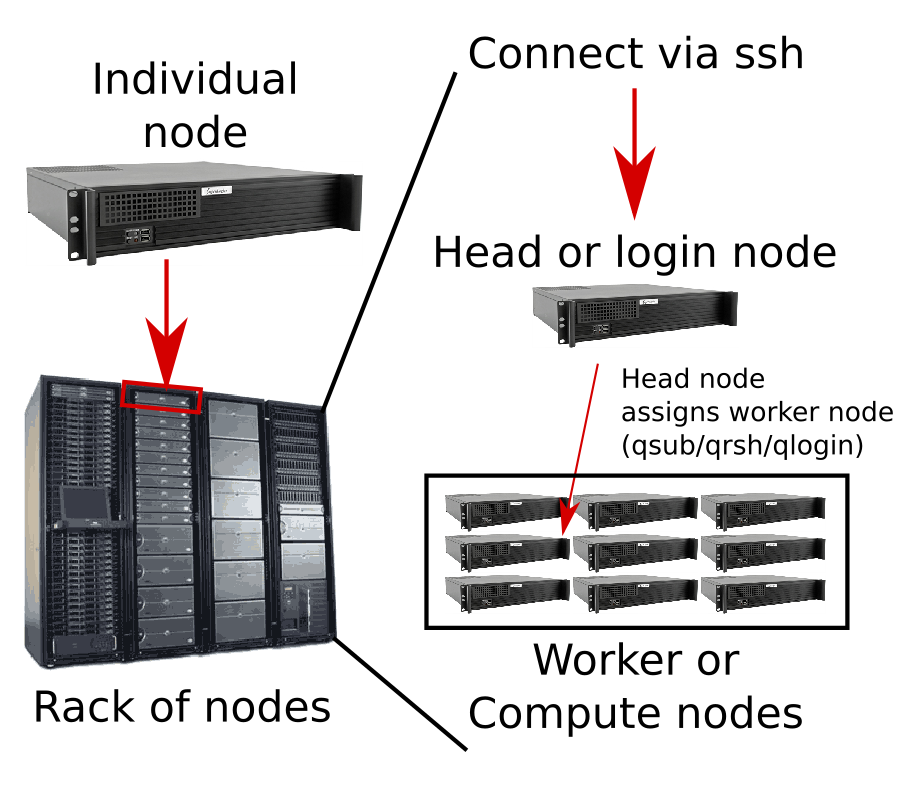
Below are some key terms and definitions for using a cluster:
- node
- Individual computers, or nodes are installed into racks and connected by high speed network connections to each other and usually to large shared storage disks.
- worker node or compute node
- Most of the nodes on a cluster are dedicated for performing computations and are called worker or compute nodes. There may be hundreds or thousands of such nodes, but most of them are not directly accessible.
- head node or login node
- A small number of nodes are designated as head nodes or login nodes that users connect to directly, and then request certain types of computational resources for running programs on the cluster using special cluster management software. The purpose of a head node is to prevent users from manually running jobs on worker nodes in an uncoordinated and inefficient manner, and to manage the resources on the cluster in the most efficient way possible. Computationally intensive processes should not be run on head nodes. You’ll likely get curt emails from the system administrators if you are found doing so!
- job
- The cluster management software then examines the resources of a request, identifies one of the worker nodes that matches the requested resources, and spawns the requested program to run on that worker node. A request that has been allocated to a worker node is called a job.
- batch job
- Jobs that are submitted to the cluster to run non-interactively are called batch jobs. These jobs are managed by the cluster software directly and the user does not interact with them as they run. Any terminal and program output are written to files for later inspection.
- interactive job
- Interactive jobs are jobs allocated by the cluster management software that give a user an interactive shell, rather than running a specific command. Interactive jobs are not intended for running computationally intensive programs.
- slots
- One resource a job may request is a certain number of slots. A slot is equivalent to a single core, so a process that runs with 16 threads needs to request 16 slots in its request. A job requesting slots must in general be run on a worker node with at least the requested number of slots. For example, if a job requests 32 slots, but the largest worker node on the cluster only has 16 cores, the job request will fail because no worker node has resources that can fulfill the request.
- resources
- Cores are only one type of resource configured on a cluster. Another type of resource is main memory (i.e. RAM). Some worker nodes have special architectures that allow very large amounts of main memory. For a job that is known to load large amounts of data into memory at once, a job must request an appropriate amount of memory. Another resource is the amount of time a job is allowed to run. Jobs usually have a default limit, e.g. 12 hours, and are forceably killed after this time period if they have not completed.
- parallel environment
- A parallel environment is a configuration that enables efficient allocation of certain types of resources. The most common use of parallel environments is to submit jobs that request more than one slot. The correct parallel environment must be supplied along with the request to have the job run on an appropriate worker node.
Cluster computing tools¶
Users interact with the cluster from the head node with commands included in the cluster management software suite installed on the cluster. Oracle Grid Engine (OGE), Torque, and SLURM are some common cluster management software suites, but there are many others. The specific commands for interacting with the cluster management system vary based on the software suite, but the ideas above are for the most part applicable across these systems. The remainder of this guide will focus on the commands that are specific to the Oracle Grid Engine (OGE) and Torque.
qsub¶
Basic usage¶
Submit a batch job. The usage of qsub goes as follows:
qsub [options] <script path> <arguments>
Here, <script path> is a path to a script file, which may be any kind of
text-based script that can be run on the command line and contains a shebang
line (see Making shell scripts executable). This is often a shell script that
includes the specific commands desired to run the batch job, but may also be, e.g.
a python script. Shell scripts that are submitted as qsub script often have the
.qsub extension to signify it is intended to be submitted to qsub. For
example, consider the file named hello_world.qsub:
#!/bin/bash
echo hello world
cat nonexistent_file
The script starts with a shebang line indicating which program is a bash script followed by a single command. To submit the script:
$ qsub -P project -o hello_world.stdout -e hello_world.stderr hello_world.qsub
Your job 2125600 ("hello_world.qsub") has been submitted
$ ls hello_world.* # after the job has completed
hello_world.qsub hello_world.stderr hello_world.stdout
$ cat hello_world.stdout
hello world
$ cat hello_world.stderr
cat: nonexistent_file: No such file or directory
The qsub command submits hello_world.qsub to the system for execution as a
batch job. The command line arguments provided are interpreted as follows:
-P project # a project name is sometimes required for accounting purposes
-o hello_world.stdout # write the standard output of the command to this file
-e hello_world.stderr # write the standard error of the command to this file
Cluster administrators often organize users into projects, that enable tracking,
accounting, and access control to the cluster based on a project’s permissions.
On some systems, supplying a project with the -P flag is required to submit
any jobs.
Instead of supplying these arguments to qsub on the command line, they may also
be included in the script itself prefixed with #$:
#!/bin/bash
# equivalent to the above, do not need to specify on command line
#$ -P project # a project name is sometimes required for accounting purposes
#$ -o hello_world.stdout # write the standard output of the command to this file
#$ -e hello_world.stderr # write the standard error of the command to this file
echo hello world
cat nonexistent_file
When a qsub script is submitted it enters a queue of jobs that are not yet allocated to a worker node. When a resource has been allocated, the requested job dequeues and enters a run state until it completes or exceeds its run time.
Requesting multiple cores¶
When submitting a job requiring multiple threads, an argument specifying the
number of slots must be provided in the form of a parallel environment. The
name of the parallel environment required varies based on how the cluster
administrator set up the system, but a complete list of locally configured
parallel environments can be viewed with the qconf command:
$ qconf -spl | head
mpi
mpi12
mpi128_a
mpi128_n
mpi128_s
mpi16
mpi20
mpi28
mpi36
mpi4
Check with your cluster administrator for how to submit multicore jobs on your cluster.
In this example the parallel environment needed to submit a job with multiple
cores is named omp. The following script submits a job requesting 16 cores:
#!/bin/bash
#$ -pe omp 16
#$ -cwd # execute this qsub script in the directory where it was submitted
echo Running job with $NSLOTS cores
# fake command, that accepts the number of threads on the command line
./analysis.py --threads=$NSLOTS
The $NSLOTS environment variable is made available when qsub runs the batch
job and is equal to the number of slots requested by the job.
Running executables directly¶
Executable commands may also be submitted as jobs to qsub using the -b y
command line argument. This may be useful when an explicit qsub script is not
needed because only a single command needs to be run. The following script and
qsub command are equivalent:
$ cat hello_world.qsub
#!/bin/bash
#$ -P project
echo hello world
$ qsub hello_world.qsub
Your job 2125668 ("hello_world.qsub") has been submitted
$ ls hello_world.qsub.*
hello_world.qsub.o2125688 hello_world.qsub.e2125688
$ cat hello_world.qsub.o2125688
hello world
$ qsub -P project -b y echo hello world
Your job 2125669 ("echo") has been submitted
$ ls echo.*
echo.o2125689 echo.e2125689
$ cat echo.o2125689
hello world
Command line arguments to scripts¶
Command line arguments may be passed to qsub scripts as with any other shell script. This may be useful for generalizing a qsub script to process multiple files:
$ cat command_w_args.qsub
#!/bin/bash
#$ -P project
#$ -cwd
echo $1 $2
$ qsub command_w_args.qsub arg1 arg2
Your job 2125670 ("command_w_args.qsub") has been submitted
$ ls command_w_args.qsub.*
command_w_args.qsub.o2125670 command_w_args.qsub.e2125670
$ cat command_w_args.qsub.o2125670
arg1 arg2
qrsh / qlogin¶
qrsh and qlogin are synonymous commands for requesting interactive jobs. They use many of the same command line arguments as qsub:
$ hostname
head_node
$ qrsh -P project
Last login: Thu Jun 8 14:36:43 2017 from head_node
$ hostname
some_worker_node
qstat¶
qstat prints out information about jobs currently queued and running on the
cluster. By default running qstat will print out information on all jobs
currently running, not just your own. To print out information on just your own
jobs, provide the -u <username> argument to qstat:
$ qsub hello_world.qsub
Your job 2125674 ("hello_world.qsub") has been submitted
$ qstat -u my_username
job-ID prior name user state submit/start at queue slots ja-task-ID
-----------------------------------------------------------------------------------------------------------------
2125674 0.00000 hello_worl my_username qw 10/15/2017 17:094 2
$ # wait until job dequeues
$ qstat -u my_username
job-ID prior name user state submit/start at queue slots ja-task-ID
-----------------------------------------------------------------------------------------------------------------
2125674 1.10004 hello_worl my_username r 10/15/2017 17:09:35 some_worker_node 2
The state column lists the state of each job you have submitted. qw means
the job is still queued and has not been allocated. r means the job is
running.
Sometimes it is useful to look at the specifics of a job request while it is
running. To view all the details of a job submission, use the -j <jobid>
command line option:
$ qsub hello_world.qsub
Your job 2125675 ("hello_world.qsub") has been submitted
$ qstat -j 2125675
qdel¶
qdel is the command used to remove a queued job or terminate a running job:
$ qsub hello_world.qsub
Your job 2125676 ("hello_world.qsub") has been submitted
$ qdel 2125676
Job 2125676 has been marked for deletion
$ qsub hello_world.qsub
Job 2125675 has been marked for deletion
$ qdel -u my_username
Jobs for user my_username have been marked for deletion
qsub script templates¶
Basic script¶
#!/bin/bash
#$ -P project
#$ -cwd
#$ -o basic.stdout
#$ -e basic.stderr
# command
Multiple job slots¶
#!/bin/bash
#$ -P project
#$ -cwd
#$ -o multicore.stdout
#$ -e multicore.stderr
#$ -pe omp SLOTS_HERE
echo Cores requested: $NSLOTS
Long running time¶
#!/bin/bash
#$ -P project
#$ -cwd
#$ -o long_run_time.stdout
#$ -e long_run_time.stderr
#$ -l rt_h=24:00:00 # run for 24 hours max
# command
qsub Command line arguments¶
qsub -P project -o hello_world.stdout -e stderr -cwd -b y echo hello world